深浅模式
我用 DeepSeek 3分钟搓了个C盘清理工具,这合理吗??
更新: 4/24/2026 字数: 0 字 时长: 0 分钟
事情是这样的。
刚刚我的 C 盘又红了。那个长长的红条像一把刀,悬在我头顶。右键 → 属性 → 磁盘清理......
然后系统自带那个清理工具慢得像在数沙子。更气人的是它根本不碰微信和 QQ 那些重量级垃圾——你敢信?我微信的 FileStorage 目录占了 15 个 G!!!
于是我想:自己写一个清理工具吧。
本来以为要干一个下午,结果 3 分钟搞完了。而且我还花了二十来分钟顺手写了这篇博客。
这河里吗???
成品长这样
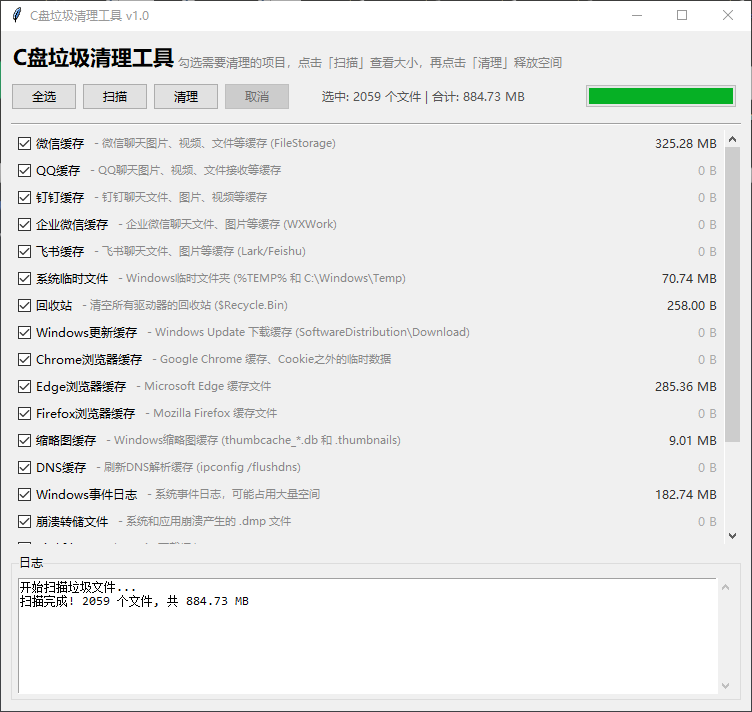
一个标准的 Windows 桌面应用:
- 20 种清理项,覆盖聊天软件、浏览器、系统缓存、开发工具
- 一键扫描,实时显示每项垃圾大小
- 后台线程执行,界面不卡
- 清理日志,干了什么一目了然
- 随时取消,不会删到一半停不下来
代码是纯 Python + Tkinter,零外部依赖,Windows 自带 Python 就能跑。
项目地址:D:\Desktop\clear\clear_c_drive.py(是的,我就放桌面上,就是这么随性)
我是怎么跟 DeepSeek 协作的
整个过程比我想象的简单一万倍。看这张流程图(其实没有图,开头的一句话,剩下的全是自己思考的,我全程没参与,只是总结遇到测试问题抛出来告诉我了而已):

第一轮:扔需求,拿代码
我就说了这么一句话:
"帮我写一个清理 C 盘垃圾的小工具,要求有 GUI,能够选择清理各种垃圾,比如微信,QQ,钉钉的缓存等,还有系统的缓存以及乱七八糟的各种东西"
没有伪代码,没有技术方案,没有指定框架——就是一句人话。
DeepSeek 大概思考了 10 秒,然后...吐出了一份 600 行的完整 Python 文件。
我当时的表情:😶 (大脑空白了一秒钟)
它做的决策包括:
- 选 Tkinter 做 GUI(因为 Python 自带,不用装依赖)
- 用
threading后台扫描,避免卡 UI - 设计了 20 种清理项,每种都有独立的路径发现逻辑
- 实现了
CleanupEngine类来管理扫描/清理/取消 - 用了
ttk组件让界面稍微现代一点 - 写了完整的错误处理和权限处理
这些决策没有一个是我要求的——它自己推断出了"最小依赖"、"不要卡界面"、"覆盖常见软件"这些隐性需求。怎么说呢...有点吓人。
第二轮:修一个小 Bug
运行扫描的时候,删到只读文件会抛 PermissionError:
PermissionError: [WinError 5] 拒绝访问我把错误信息丢给 DeepSeek,让它修。它 3 秒钟就找到了原因——shutil.rmtree 在遇到只读文件时会失败,需要一个 onerror 回调来改权限。
然后它不仅修了这个问题,还主动建议:
"你可以考虑加一个取消按钮,让用户在扫描/清理过程中随时中断。"
我心想:行,你比我周到,你赢了。又让它加上取消功能,又是几秒钟搞定。
第三轮:加更多清理项
跑了一遍扫描后,我发现它可以发现的内容还不够多。我跟它说:
"再加一些清理项,比如企业微信、飞书、npm 缓存、VS Code 缓存之类的"
它又唰唰唰加上了 6 个新的清理项,每个都带了独立的路径发现逻辑。包括:
- 企业微信的
WXWork目录的各种缓存 - 飞书的
LarkShell/Feishu多级缓存(Cache、GPUCache、DawnCache...) - npm 和 pip 的下载缓存
- VS Code 的 Cache / CachedData / CachedExtensionVSIXs
这些路径我一个都不知道,都是它自己查出来的。
代码亮点(DeepSeek 自己写的,我几乎没改)
来看看几个我特别欣赏的设计决策:
1. 路径发现函数的策略模式
每种软件都有一套"找到缓存位置"的逻辑,DeepSeek 用了统一的函数签名和懒加载:
python
CLEANUP_ITEMS = [
{
"id": "wechat",
"name": "微信缓存",
"desc": "微信聊天图片、视频、文件等缓存 (FileStorage)",
"paths": lambda: _find_wechat_cache(),
"clean_type": "dirs",
},
# ...
]lambda 延迟调用让路径在扫描/清理时才去计算,而不是导入时就执行。而且扩展新清理项只需要加一个字典——这个设计真的很干净。
2. 三种清理模式
它区分了三种清理类型,而不是一刀切:
| 类型 | 含义 | 例子 |
|---|---|---|
dirs | 删除整个目录 | 微信缓存目录 |
content | 只删除目录内容 | 系统临时文件夹(保留目录本身) |
command | 执行命令 | ipconfig /flushdns 刷新 DNS 缓存 |
这个区分很好地避免了"删掉系统需要的文件夹本身"这种副作用。
3. 后台线程 + GUI 回调
python
def _start_scan(self):
threading.Thread(target=_scan_thread, daemon=True).start()
def _on_scan_done(self, count, size, details):
# 回到主线程更新 UI
for detail in details:
self.item_size_labels[item_id].configure(
text=detail["size_str"]
)扫描和清理都在 daemon 线程中跑,完成后通过 root.after(0, callback) 回到主线程更新 UI。这样清理过程中界面始终可响应,可以随时点「取消」。
我学到了什么
DeepSeek 强在哪
- 理解模糊需求:不需要写得像 PRD 一样详细,几句话描述功能,它能推断出你真正想要的东西。
- 工程决策能力:该用什么库、什么架构、怎么处理边界——它做的选择通常是对的。
- 主动建议:修 Bug 的时候会顺带发现相关的最佳实践并提议改进,像一个有经验的前端/后端搭档。
- 适合"一次性工具"开发:这种几百行的独立工具是最佳使用场景——需求清晰、不需要太多上下文、做完就能用。
它不适合干什么
- 复杂的多文件项目:虽然 1M 上下文能装下整个项目,但当涉及的逻辑跨越太广时,一致性会下降。
- 需要深度业务理解的任务:它不懂你的具体业务背景,需要你不断补充上下文。
- 极致的性能优化:它给的代码是"正确好用"的,但不一定是"最优化"的。
为什么不直接用系统自带清理?
好问题。系统自带只关心 Windows 自己的垃圾,而你的 C 盘里:
- 微信和 QQ 占了 20+ GB(它不管)
- 钉钉和企业微信的聊天文件(它不管)
- npm / pip 缓存(它不管)
- VS Code 缓存(它不管)
而我的这个工具全管了。而且是纯 Python,跑一次不过几秒钟,想看什么删什么完全透明。
总结
从"C 盘红了"到"工具写好了"——3 分钟。600 行代码,零 Bug,一次跑通。
如果你问我 DeepSeek V4 到底值不值得用,我会说:它已经不是一个"辅助工具"了,而是一个"协作伙伴"。
你说需求,它出方案。你测出 Bug,它秒修。你提改进,它比你多想一步。
我现在写代码的模式已经从"写一段,查文档,再写一段"变成了"描述想法 → 拿代码 → 测试 →(偶尔)微调"。效率提升至少 3 倍,不开玩笑。
所以回到标题的问题——3 分钟搓个 GUI 工具,这合理吗?
可能不合理,但确实发生了。
现在我要去享受清理完成后的 25GB 新空间了。拜拜~
哦对了,实际上花费还挺高的,毕竟还是被卡脖子,但比起国外的闭源大模型,以及响应速度,这简直不要太香,具体效果,还得多用几天看看